Following the release of OpenAI’s ChatGPT, a tide of new educational resources washed in aimed at educating newcomers about large language models (LLMs). Some of these resources were overviews of concepts and companies; others were tips and tricks guides (”this one prompt will save you hours!”); and still others were hands-on tutorials of working with APIs, packages, and various models themselves. As introductions to the terms, concepts, techniques, and technologies, these resources—what I call here “getting started guides”—serve as first steps in the journey of some to understand and use LLMs.
After some hesitation, I myself was pulled in. I am not a developer, but a designer and researcher with some very dusty front-end development experience. As such, I decided to start at the very beginning with fairly basic tutorials and conceptual overviews because, frankly, I was deeply intimidated by the domain. A lot of folks seemed to know a lot about what was going on—and I felt at a loss.
The getting started guides varied in form, content, and effectiveness, yet had similar currents. I noticed that certain names repeated: OpenAI, Google, Langchain, HuggingFace. I noticed the same diagrams of how models worked, and similar explanations and steps of how an LLM makes sense of prompts. I noticed that companies often wrote these resources, often promoting companies on which their own offerings depended. I also noticed the frequent absence of considerations such as the data underlying the models, their potential for bias, and the ways things go wrong. (Those concerns seemed left for reporters.) Most of all, the guides emphasized getting started fast.
Although my intention was to learn about LLMs, I found myself learning about something else too: the guides themselves. After looking a little deeper and shoring up hunches, I decided to catalog and review getting started guides for LLMs in order to understand what getting started guides tell us about the emerging shape and bearing of the generative AI domain.
The following post provides a review at what I found. First, I provide a personal anecdote about what led me to look at the guides rather than just what the guides were teaching. This is effectively the preamble to a recipe—if that’s not your thing, jump ahead. Second, I explain the methodology and its limitations. Third, I detail the findings and their implications. Following the findings, I discuss the implications of what has been shared.
The thesis of this post is that getting started guides illustrate that closed and proprietary models and services are becoming default choices for early learning, while alternative open models and services are positioned as conceptual alternatives. The relative positioning of these two camps reflects and reinforces wider industry activities, and so shows a site where commonsensical dispositions and expectations circulate that influence what it means to make (with) generative AI.
Definitional note: getting started guides are fuzzy
I use the term “getting started guides” to refer to a fuzzy category of educational materials that are intended to quickly introduce individuals to a new domain and set these individuals up for continued learning. Getting started guides exist for all sorts of topics, but I myself see a great deal of these working in technology. The reason I think getting started guides are so common in tech is that technology supposedly changes quickly, speed is operative in capitalism, and continued professional development is a technology worker’s response to the precariousness of these forces.
Regardless of the topic and reason getting started guides exist, three characteristics tend to define the getting started guide category in tech and elsewhere:
- Self-directed: Getting started guides assume that learners are learning on their own. As such, guides tend to be self-contained in their content and on-demand in their access.
- Informal: Getting started guides assume that learning is happening in an informal context, and often a temporally constrained context (hence needing to be quick guides). As such, the tone is not overly formal, though at times it can be jargony. The introduction of jargon is an important contribution of getting started guides as jargon is a marker of cultural affiliation, and these guides aim to onboard someone into a domain so they can be effective in that domain.
- Pragmatic: Getting started guides emphasize—even when giving an overview of concepts—useful information. The point is not knowing what something is, but knowing how to make use of something. The emphasis on know-how means reflections, debates, and discussions are footnotes, if included at all.
For the sake of reiterating, in the context of this post, when referring to getting started guides henceforth, I mean in particular getting started guides for LLMs.
Anecdote: why getting started guides are important?
The thought that getting started guides are useful artifacts to understand the culture and industry of generative AI came to me while reading my first tutorial. The tutorial, titled “Getting Started with LangChain: A Beginner’s Guide to Building LLM-Powered Applications” (25 Apr 2023), is written by Leonie Monigatti for the publication Towards Data Science, which is published on the platform Medium. (Candidly, the tutorial was way over my head at this initial reading.) In this tutorial, the author includes “a personal note” that stood out as more than just personal and just note. Instead, the paragraph contained what felt like a signpost for where generative AI might be headed. The note appears about a fifth of the way into the article, just past the introduction and first code snippets that connect a newbie to an API. The note reads:
Let’s be honest here for a second: Of course, you can experiment with open-source foundation models here. I tried to make this tutorial only with open-source models hosted on Hugging Face available with a regular account (google/flan-t5-xl and sentence-transformers/all-MiniLM-L6-v2). It works for most examples, but it is also a pain to get some examples to work. Finally, I pulled the trigger and set up a paid account for OpenAI as most examples for LangChain seem to be optimized for OpenAI’s API. Overall running a few experiments for this tutorial cost me about $1. (source)
Simply, the note is practical advice: it shares a path of least resistance given the author’s expertise. As anyone getting started with a new endeavor knows, early bumps can be frustrating and disruptive, and may even derail further learning. In that way, the personal note seems like a kind arm around the learner’s shoulder: “Hey, I’ve been there and here’s what I’d do if I could do it again…”
But this advice is more than just about avoiding missteps. The note advocates against specific alternatives and for specific companies, as well as suggests that moving quickly with the least effort or resistance should trump other considerations. As a newcomer myself and working for Mozilla—a company with a history of open-source software development—I wondered: “Can this be true? Certainly there is a place for open-source here, right?”
What I did not know when I first encountered it, the tutorial itself is a microcosm of getting started guides and seemingly the emerging shape of generative AI. In the subsequent code examples, HuggingFace is abruptly absent, and so alternatives cede the floor to OpenAI. The examples teach how to use Langchain with OpenAI rather than, as the title suggestions, how to use Langchain in general. The result is a tutorial that nudges readers to continue down the path of depending on OpenAI because, well, that is all they learned how to use.
I finished this tutorial with a number of questions about the conditions that surrounded its existence. For me, this tutorial illustrated that getting started guides are opinionated in ways that, regardless of how explicit they are, reflect and contribute to dispositions, tendency, and dependencies around making (with) generative AI. As such, the goal became finding a means to zoom out from one tutorial to many, and share that vantage point.
Methodology
Research question
The impetus for this research was to provide an answer to the following question: what do getting started guides tell us about the emerging shape of the generative AI domain? Although a starting point, this initial question is hard to answer directly. As such, the following research is more narrowly focused on the following question:
As artifacts of the material culture of generative AI, what values, dependencies, and interests are contained in getting started guides about the ecosystem and industry that is emerging around generative AI and specifically large language models?
Thinking of getting started guides as cultural artifacts helps us answer questions about how generative AI is not just a made up of technologies and technical practices, but also made of dispositions, attitudes, expectations, and values that are shared, learned, localized, and morphed over time.
Data gathering
The data gathered for this research was done so as follows:
Queries
To gather resources, I did four different web searches. I used Google search in a private window of the Firefox browser. These web searches were:
- “getting started with LLMs”
- “beginner’s guide to AI”
- “LLM introduction”
- “LLMs intro”
I ran the web searches at the end of July 2023.
Collecting
From each query, I gathered the top 20 links. Because I used Google, these results included promoted links (actually only one promoted link was found), YouTube videos, and links organized by Google’s relevancy ranking.
Analysis
After constructing a database of getting started guides, I visited each link and read what it contained. To begin, I used a half-open coding schema to catalog observations; that is, I started with a few pre-existing codes (e.g. mentions of OpenAI and HuggingFace; existence of code snippets) and added additional emergent codes (e.g. the type and format of the guide) as I read and reviewed documents. Codes were applied in subsequent iterations of reviewing documents, until a final pass was done to ensure consistency in their use.
The coding schema included descriptions of the documents in terms of their type and format, the location and production of the guide, and the guide’s contents (e.g. mentions of OpenAI and HuggingFace, inclusion of code snippets).
The analysis seeks to answer the research question through observable instances and their interpretation. All claims refer to the data (those guides gathered) rather than a generalization of all guides, yet I use these data to provide provisional claims about the emerging AI industry and ecosystem. I do so by assuming that getting started guides are cultural artifacts. As such, each guide is made because of and contributes to wider milieu that can be called the domain and industry of generative AI. I use numeric data—percentages and quantities—not to refer to the overall distribution of getting started guides, but to the distribution of the guides that were found.
In total, this methodology produced sixty (60) unique getting started guides out of a maximum of 80 potential guides. Accounting for this different is that eight (8) of the original set were deemed irrelevant and twelve (12) were found in more than one query (duplicates). These guides are the basis for the subsequent findings.
Limitations
The data gathered in this approach are but one snapshot of what is available. As such, the same queries conducted in the same way would likely produce different results now due to changes in the available resources and their relevancy ranking. Moreover, using different search engines (e.g. DuckDuckGo, Bing, Brave) or specific user preferences would produce different outcomes (though I am not sure in what ways browser or search history impacts results precisely in this domain). Likewise, the presumption that learning begins with a web search characterizes only some learning pathways, and excludes individuals that start using, say, social media, communities, or learning platforms (e.g. Substack, Reddit, Mastodon, Udemy, DataCamp).
(As much as comparative analysis would be useful, I am not certain if I will iterate on this study. I would encourage others to contribute to the body of knowledge around getting started guides by performing the same, derivative, or altogether new methodologies with respect to getting started guides, as well as analyzing these and other aspects of the material culture of AI through other lens and artifacts. If you take on the task of collecting getting started guides—even with a list of links or screenshot of what you find—please reach out in the event I find renewed energy!)
Findings
Types
According to the data collected, getting started guides for LLMs fall into three types: conceptual overviews (63%, 38 of 60), first-step tutorials (28%, 17 of 60), and learning repositories (6%, 4 of 60). These types of guides are mutually exclusive, though have overlaps in their composite parts.
Conceptual overviews
Conceptual overviews explain the ideas, technology, and processes of LLMs using key terms and jargon, reference points (such as papers, companies, and historical events), and presumed knowledge given the intended audience (such as ideas related to software engineering like abstraction). Together, these features enable subsequent learning by introducing concepts found within other (presumably subsequent) in-domain learning resources. These guides use textual and video explanations; diagrams, illustrations, and animations; and narratives (examples, metaphors) to accomplish this broad overview.
The core of conceptual overviews for LLMs is breaking down processes into steps and technologies into components. The explanations in conceptual overviews are relatively high-level—and authors sometimes acknowledge this fact—and so presume subsequent learning is needed in order to develop and use LLMs. The acquisition of language (both terminology and jargon), concepts, and resources (including companies to know and products to consider) are the primary learning outcomes of conceptual overviews. All told, the main purpose of conceptual overviews is demystifying LLMs, and so contributing practical knowledge with regards to grounding and navigating subsequent learning.
First-step tutorials
First-step tutorials are distinct from contextual overviews with one key feature: these guides provide code snippets or code notebooks to support experiential learning with LLMs. Many of the features of conceptual overviews are part of first-step tutorials. The introduction of terms, jargon, concepts, and processes fill the preambles of first-step tutorials. Introducing companies-to-know and offerings-to-use happens upfront as well as through coding examples, where the offerings and tools are used for various tasks.
After preambles, first-step tutorials guide learners through setting up prerequisites. These prerequisites include, amongst other tasks, setting up API access (such as with OpenAI and HuggingFace to access models) and installing packages from the command line (such as Python packages for storing embeddings, accessing models, and structuring prompts). The reason for this starting point is presumably because the audience has not worked with LLMs in this manner yet. Establishing this baseline for development (e.g. APIs, packages, etc.) is a key contribution of first-step tutorials as it makes subsequent learning-through-coding less cumbersome upfront.
Following the prerequisites, first-step tutorials walk through coding examples that illustrate the ways LLMs operate. Some of these examples include sentence completion, answering trivia, coming up with recipes or company names, summarizing texts, and determining the sentiment of a sentence. Within these tasks are gestures that reinforce using specific offerings (e.g. API keys, function calls to particular models or services) and domain techniques for making LLMs workable. Domain techniques include using hyperparameters (typically just temperature), few-shot text classification, prompt templates, and fine-tuning, all of which are specific generative AI. These coding examples illustrate through experience what an LLM is and does, and provides an initial foundation for subsequent experiential learning.
Learning Repositories
Learning repositories (or “learning repos”) comprise the remaining getting started guides. Given how few were found—only 4 of 60 guides fall into this category—claims beyond high-level descriptions lack substantiation. What seems to be the main feature that distinguishes learning repos from other guides—and the reason to mark distinction with so few instances—is that learning repos provide outlines of materials and relationships of those materials rather than the content of the learning itself. In other words, learning repos index learning. Of the learning repos found, some features include grouped lists of books, links, and other resources; explanations of what one could expect to learn and why (similar to an annotated bibliography); and sequencing and stages of advancement through material.
Encompassed in learning repos are what might be called curricula that structure learning progressively through levels or stages of knowledge and skill acquisition. Also encompassed in learning repos are organized collections of materials (e.g. link lists grouped by topic or type) that lack the progressive learning structure of a curricula, but nonetheless comprise a means to build domain understanding. In these ways and like the other guides, learning repos exist to accelerate domain knowledge, albeit by providing a foreshortened means to find resources for that accelerated learning.
From the guides found, several distinct formats exist. These types are listed based on the number of observations:
Single-page (37 of 60, 62%): The most observed format is single-page (38 of 60). As the name states, single-page guides are, unsurprisingly, a single webpage that flows from top to bottom. Conceptual overviews and first-step tutorials are found in single-page format.
Video (9 of 60, 15%): The second most observed format is video, namely YouTube videos. Given the means of data collection, the number of videos is a feature how Google prioritizes YouTube within its search results pages. As such, in the subsequent discussion of where getting started guides are found, YouTube videos are excluded as to remove a known bias from the means of data collection. That being say, Pew Research Center has found YouTube is a common site where learning occurs. Even still, to determine whether the video format in general and YouTube in particular are significant to learning about LLMs, data collection would need to be done through a different methodology.
Course (7 of 60, 12%): The third most observed format is the course. The course format breaks down learning into sequential and progressive modules or stages. To deliver learning in this fashion, courses are hosted on courseware sites that stage progressive learning and host content, including text, videos, and interactive activities (e.g. quizzes, clickable examples). Courses may include some form of measured evaluation, and almost always provide certificate of completion. Conceptual overviews and first-step tutorials are found as courses. No instances of learning-repos-as-courses were observed, though learning repos were a component of some courses in the form of reading lists.
Index (4 of 60, 6%): The next format of note is the index. The distinction between type and format is one of content and structure, respectively. In the case of the index and learning repository, type and format are coupled as the learning repo is defined as an index of learning resources.
Ebooks (2 of 60): The last format of note is the electronic book or ebook. The two ebooks are distinct in that they are not native web formats, but instead are portable document files (PDFs). The format itself and the writing in terms of content and style seem to presume a distinctly different audience than other getting started guides. For example, one of the ebooks is produced by the company Databricks and requires sign-up on a landing page to download the ebook and includes a pitch for technical consulting with the company. The other two-part ebook is produced by Nvidia and includes industry case studies and the benefits of LLMs for enterprises. I would venture to say that these ebooks are lead generation tools for companies seeking to court executives and product managers through business intelligence as much as they are conceptual overviews of LLMs.
Location and production: where are they and who’s making them
According to the data collected, getting started guides are found on two main types of website (location) when excluding YouTube (see: Formats>Video), and several minor types of websites.
Learning sites (23 of 51, 45%): Learning sites include courseware sites (e.g. Data Camp), publishing platforms (e.g. Medium), and peer learning communities (e.g. Kaggle). Learning sites are framed as places of learning, whether formal or informal. Medium itself is the most prevalent single site/platform amongst the guides collected.
Company sites (21 of 51, 41%): Company sites include all guides found on domains or subdomains controlled by a company, including blogs and landing pages.
The remaining guides were found on LinkedIn (type: professional social network), GitHub (type: code repository), and websites run by individuals (type: miscellaneous).
For the guides found, eleven (11) were access controlled, ten (10) of which of which were on learning sites. Access was managed with payment (e.g. a Medium membership) or registration (e.g. creating an account or sharing personal information). When accounting for access, company websites and blogs account for the majority of freely accessible guides about LLMs.
When considered from a different perspective, we see production is entangled in the companies working in this domain regardless of where a getting started guide is found. Of the 60 guides, 28 (47%) were written by a company. The majority of these guides were housed on company sites, but others were found on learning sites and YouTube. Moreover, 16 (27%) of all the guides collected promoted a product, service, or resource with which the producer/author was affiliated at the time of publishing. In this, we see that a large number of guides blur the line between education and promotion, and so making learners into potential customers.
The use of getting started guides as marketing and promotion is by no means surprising, but worth mentioning explicitly. Content marketing has long-been established as a means drumming up business for companies, whether in the form of generating leads or promoting offerings through education. In the case of LLMs, getting started guides are opportunities to catch those just beginning to learn about the domain. In that, getting started guides are amongst “top of the funnel” tools for companies in this domain. Moreover, guides are used to funnel potential users, customers, and clients in two ways: through promoting products themselves and through name recognition amongst those learning in this space.
In the next section, name recognition is focused on in a different way: regardless of who produces a getting started guide, what names frequent its contents.
Technology stack: entrenchments and alternatives
An important feature of getting started guides is what technologies and companies are promoted therein. As individuals develop skills and understanding, the particulars of that knowledge are important. When a guide includes an API, for instance, learning may depend exclusively on capabilities, expectations, and gestures unique to that company or offering. As such, the inclusion of specific technologies, frameworks, techniques, and their accumulation—what is typically called the “tech stack”—cannot be separated from the knowledge gained in some—iof not, many—instances. As such, commonsensical choice starts as an initial suggestion and reinforcement.
To focus the inquiry on what is becoming commonsense, I focus on two camps and specific proxies within each.
Closed camp: One camp is closed-source and proprietary LLMs and services. The focus of the closed camp is on mentions of OpenAI and use of OpenAI’s services and models. In this camp are other companies, including Google, Cohere, Nvidia, and Databricks. I only call out OpenAI and Google in the analysis because they capture the other proprietary mentions.
Open camp: The other camp is open-source and openly-accessed LLMs and services. The focus of the open camp is on mentions of HuggingFace and use of HuggingFace’s Interference API and Transformers tools. Other companies and models exist—such as BigScience and TII’s Falcon—which are grouped within the open camp together.
A clear theme is that LLMs are dominated by the closed camp Of the 60 getting started guides, 46 (77%) explicitly mention OpenAI in both name and in code instances. Four (4) additional guides—totaling 50 guides (83%)—mention OpenAI implicitly by way of reference to OpenAI’s ChatGPT. These mentions are only in name alone, that is, do not include code examples. 53 (88%) of all guides mention products, services, and models from the closed camp. The three additional guides are written by Google and exclusively mention models Google created, and none of these include code snippets. As such, OpenAI constitutes the bulk of individual mentions. No guides are produced by OpenAI .
The open camp is less dominant. HuggingFace is mentioned most frequently as an alternative to OpenAI. Across the 60 guides, 15 (25%) mention HuggingFace explicitly. An additional three (3) guides—totaling 18 (30%) guides—mention or link to HuggingFace or other open-source models (e.g. LMSYS Org’s Vicuna, TII’s Falcon, Big Science’s BLOOM). No guides are produced by HuggingFace.
Given the shape of the computational technology industry and ecosystem in general, the dominance of the closed camp is maybe not too surprising. What is more telling is where and how the open camp is found within specific types of guides. Of the 38 conceptual overviews, nine (9) mention HuggingFace and 27 mention OpenAI, with 23 of 38 (60%) of conceptual overviews only mentioning OpenAI or another proprietary model. No conceptual overviews mention HuggingFace or open-source models exclusively. Only one guide mentions an open-source model—and particularly, an open-source local LLM—as a explicit goal rather than simply an alternative to closed systems.
Of the 17 first-step tutorials, only 4 guides mention HuggingFace in coding examples, though HuggingFace is mentioned in the copy elsewhere in 3 additional tutorials. Inversely, 13 of the 17 first-step tutorials (76%) use code examples based solely on OpenAI’s offerings. When HuggingFace is mentioned in code, only one instance uses an open-source model, namely, Big Science’s BLOOM LLM. In the other three (3) instances, HuggingFace is used to interact with a Google model hosted on HuggingFace and accessed through HuggingFace’s Inference API.
In total, we see the closed camp overwhelm the open camp in terms of mentions. In no instances is HuggingFace mentioned without mention of OpenAI. Conversely, 28 of the 60 guides (47%) mention OpenAI without a mention of HuggingFace or an alternative, and 35 of 60 (58%) mention a proprietary model without a mention of an alternative from the open camp.
Discussion
Conceptual alternatives
These findings show that while open-source models and openly-accessible services exist, closed-source model and proprietary services are dominating the generative AI industry. As cultural artifacts, getting started guides illustrate that open-source models and openly-accessible services are framed within the industry and domain as conceptual alternatives to closed-source models and proprietary services. By conceptual alternative I mean that the open technologies are mentioned to make the point that closed technologies are not the only options, but that tangible examples of how to make open and closed comparable are not yet realized in the building of systems, products, services, and even coding examples. HuggingFace as a proxy for the open camp is name-checked, and then effectively disregarded by many first-step tutorials. Even in conceptual overviews, where HuggingFace is mentioned more often, HuggingFace is literally parenthetically mentioned in many instances and rendered marginal when compared to the volume and centering of OpenAI. ChatGPT, for example, has become a stand-in for generative AI in general, and OpenAI reaps the benefits of that.
This division between open and closed camps is similar to the technology industry in general, where open-source alternatives exist but not at the same scale as proprietary offerings. As such, open-source models and systems seem to lack equivalently substantive onboarding in the form of first-step tutorials that are useful for developers, and similar coding examples at higher levels of learning. The reason for this lack of coding examples is, as the personal note calls out, the performance of these alternative open offerings is not comparable or as easy. The question, then, is how did the means of comparison get established in the first place. Though I cannot say in general, in the case of getting started guides, the expectations that certain types of performance and use are desirable are established through the cultural narratives of technology production.
Narrowing in on first-step tutorials provides a glimpse of what is at work. The prerequisites and coding examples render subsequent learning less cumbersome by establishing a technical baseline for learning more. The examples teach the expectations of use and development through tasks and techniques, and so first-step tutorials also nudge learners forward on a path with particular APIs and tools, and so company. In that, first-step tutorials reflect and produce wider dispositions because their producers learned and then teach—and, in the case of companies, depend on—those dispositions as commonsense and the companies as defaults. Given that the technology industry tends towards a critical technical practice—namely, alternatives are not valued as simply possible through abstract concepts but valued as workable in concepts materialized concretely. As such, the taught-because-learned dispositions toward specific comparisons are dependent on the actual de mode techniques, technology, and products. As conceptual alternatives, open-source models and openly-accessed systems have ground to make up to be substantive alternatives in the onboarding itself as well as that which supports others building with that open tech stack.
What’s missing?
Until now the focus has been on what has been mentioned in getting started guides. But what seems absent?
A major absence from getting started guides is mention of the unpredictability of LLMs, as well as their bias, the data the models were trained on, the impact of that training, and a host of other considerations. Although the social and ethical considerations are paramount, I realize that expecting a getting started guide to delve in these issues is misplaced. Without the requisite understanding, these issues are hard to understand, let alone do anything about besides avoiding use of LLMs altogether. The unpredictability of LLMs does, however, seem like an appropriate thing to mention in getting started guides as it is very apparent and has been reported on wildly.
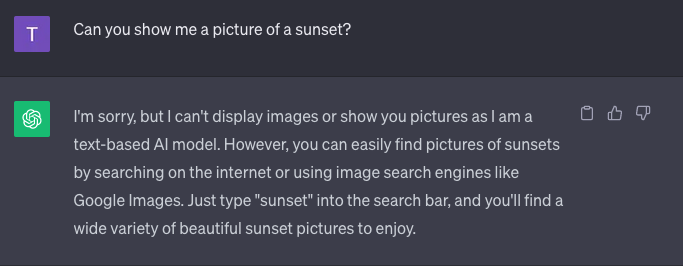
In early code examples, LLMs do not work as one might expect. Answers to seemingly simple questions—e.g. what is the capital of France?—may not be answered correctly, leading one to think the system is not working or the code written is faulty. In fact, as I have learned, if any word is produced whatsoever by an LLM that should be considered workin because LLMs are not answering a question but providing a statistical prediction of what word should follow from the preceding words. If it is factually wrong that is besides the point from the perspective of an LLM. As an expectation of these systems, the lack of mention of their inherent expected unpredictability is absent.
Mentions of the correctness of answers are few across the getting started guides collected. Of the 60 guides, I found only three (3) instances that call out that LLMs will get answers “wrong.” In other instances, getting started guides use language to frame unpredictability without explicit mention, e.g. LLMs “generate new text that is coherent and grammatically correct” (source). Implicit is that coherent and grammatically correct does not mean factually correct.
The lack of mention of these wrinkles is emblematic of the implicit goal of getting started guides. Besides teaching people about LLMs, getting started guides aim to convince newcomers that LLMs are exciting and worthy of their investment. In other words, getting started guides are material artifacts of domain boosterism. Now some producers of guides are clear about the drawbacks, yet in many cases the complexities are omitted, vaguely mentioned, or dismissed as workable. For example, bias is a major issue of LLMs, yet bias is mentioned in only five (5) guides. Most of these mentions simply say bias exists in these systems, which is efficient dismissal of bias as an issue one might consider before learning more.
In sum, getting started guides lack important information so individuals can approach learning about LLMs critically. As unreasonable as it may be to expect a deep discussion of unpredictability and bias in a getting started guide, an appropriate level of detail about the drawbacks of these systems is needed.
Conclusion
Getting started guides for LLMs are artifacts of AI’s material culture. As has been described above, they are products of and contribute to the cultural milieu of generative AI by producing and reproducing features of an ecosystem within which they exists. As such, getting started guides illustrate what those working in and around AI may see and feel elsewhere.
In particular, this post describes that getting started guides document the growing entrenchment and consolidation of the LLM technology “stack” around proprietary and closed-source models, services, and systems. Open-source alternatives, while they exist, are more conceptual alternatives rather than viable substantive alternatives—that is, alternatives ready to be used in products. With the role of staging learning, getting started guides blur the boundary between content marketing and educational resources, seemingly warming leads through name recognition and practical adoption as much as priming subsequent knowledge acquisition. These guides set expectations about what LLMs can do (and who and what can provide that doing), while kicking the can aspects that complicate their adoption and mire expectations.