Preamble: learning about AI through events
One of my approaches to learning about the industry, technology, practices, and culture of artificial intelligence is to attend various events on the topic. I am just starting out and so far have attended just three events. One event was on how to prompt ChatGPT that seemed to draw people using ChatGPT for marketing. Another event was a discussion hosted by the IxDA Atlanta where designers of various sorts talk about their use of, hopes for, and concerns about generative AI. Most recently, I went to an event where authors of a machine learning presented their research (described below). As I have found in other works, events are especially useful to find an entry point to expansive domains and, when done repeatedly, surface differences amongst groups or types of attendees. Given that AI is a massive and rapidly changing domain, attending a smattering of events is one way I am getting a handle on things.
I am finding events by searching Meetup, and doing so results in a lot of different events, these three being emblematic of what I have seen. I would say there are two camps thus far. Many—maybe most—events focus on building with the technology and introduce concepts, techniques, and tools useful for those in software development roles. Other events focus on understanding and using AI in different roles—marketing, design, product and project management, finance, and so forth. Although I am particularly interested in this second type of event—namely, events for non-builders1—I am planning on attending a mix of events to understand the differences between these two broad camps, especially with regards to the type and distribution of information and understanding.
As I attend more events, I plan to share what I experience—sometimes just thoughts; other times more substantive thinking. I’ll be using the title “Field Report” to distinguish these posts from other posts.
—
Field Report
Event: Generative AI Paper Reading - RWKV (Presented by RWKV Team)
Host: Silicon Valley Generative AI
Additional resources
- Paper: https://arxiv.org/abs/2305.13048
- Website: https://www.rwkv.com/
- Hugging Face Blog: https://huggingface.co/blog/rwkv
- Github repo: https://github.com/BlinkDL/RWKV-LM
On 11/6/2023, I attended an event hosted by Silicon Valley Generative AI. The group does a series where individuals present their papers related to the AI field. This month, the presentation focused on research on rearchitecting a specific kind of neural network called a recurrent neural network or RNN.
This was my first time attending the series and will likely not be my last. Based on just this event, the expected audience is pretty technical. This may be expected given the paper itself, but also was made explicit: one presenter glossed over explaining what RNNs were or the architecture of transformer models by remarking he assumed the audience was sufficiently familiar with the field. I found the discussion hard to parse not being a machine learning or AI expert. However, I had just enough understanding of the topic to follow the main points at a high-level, though I had nowhere near enough understanding to have any questions. After the event, I did my fair share of reading Wikipedia articles to clarify terms that the presenters used.
Despite being challenging to follow, I found the RWKV event very useful, especially as a point of comparison to the events for non-builders I have attended. In those latter events, terms like prompt were defined upfront and most people conflated generative AI writ large with OpenAI’s product ChatGPT. In other words, the gulf between builders and non-builders is very wide in terms of what they are discussing. From the events I have attended and conversations I have had, non-builders audiences have been thinking about how these made-systems impact their lives and jobs in both positive and negative ways. At the RWKV event, the focus was on how these systems become made. This is not to say non-builders are unsophisticated—in fact, these audiences are simply not talking about the same things. At the forefront of non-builder events were real concerns about day-to-day impacts and ethical concerns, which were altogether missing from the RWKV event (honestly, I am not sure where these kinds of concerns would fit, which is my point). The RWKV event did show how fast ideas are emerging and how focused builders are on AI as a technical problem—GPU saturation, memory loss, and scaling—that leaves little room for the sociopolitical world of AI.
On to the topic itself.
The paper presented focused on a revised architecture to recurrent neural networks (RNNs), a precursor to transformers. Transformers underlie the wave of models currently driving advancements and productization of AI. RNNs have largely been left by the wayside because they lack the ability to scale effectively due to a bottleneck in their architecture (Wikipedia tells me that this bottleneck results in what is called “the vanishing gradient problem”).
As I understand it, RNNs “read” sentences in order, one word followed by the next. Transformers, on the other hand, use an “attention mechanism” that allows the model to focus on key words in a sentence (many claim attention mechanisms compare to how people actually read 🤷). The result is that transformers allow for parallel processing of tasks RNNs serialize. The issue with RNN architecture is that RNNs struggle with longer input sequences due to how they store (or really lose) information overtime. This first diagram is how the presenters explain the bottleneck of RNNs (see the red arrows).
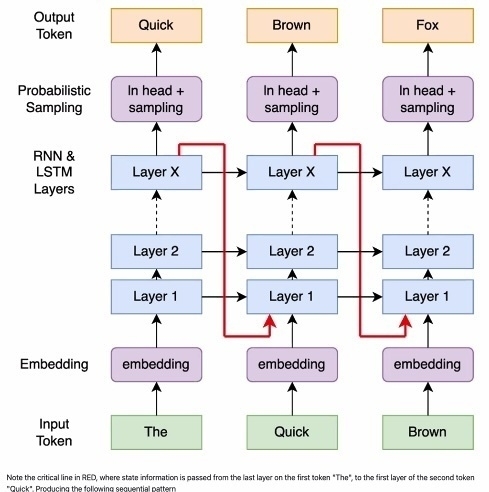
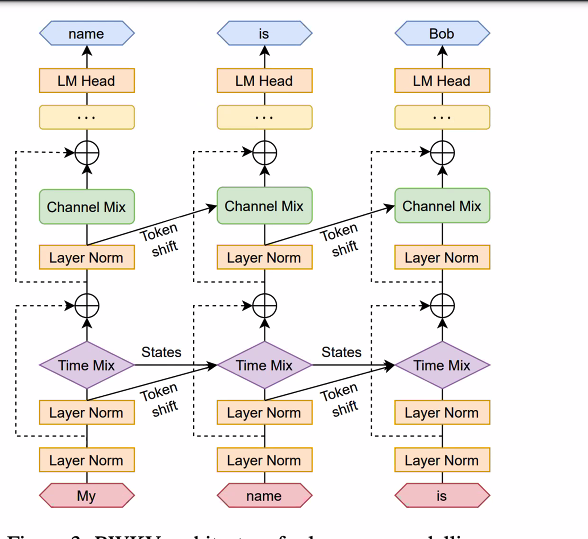
The architectural update to RNNs described in the paper is called RWKV (it has a pronunciation that I can’t remember). According to the presenters, the reworked architecture has better memory by shifting tokens to address issues of memory loss and increase parallel processing. The subsequent diagram shows strategies for preserving memory and increasing efficiency by shifting tokens, sharing states, and mixing outputs as inputs.
The authors claim that while the models themselves require comparable data to know how they perform as models, the architecture can be used to train models at sizes well beyond previous RNNs. At these sizes, RWKV architecture compares to transformer architecture (on what terms that comparison happens I am not exactly sure…I need to do a deeper dive on the paper if I can even understand it).
Why is any of this interesting to me as a non-builder? The authors explain that RNNs are far less resource intensive, scaling linearly with parameter size rather than quadratically as transformers do. If this approach can use data that is comparable to existing models (say the data underlying Llama), the upfront cost and ongoing resource use would be significantly lower as models get bigger. This means that using the RWKV architecture might be an alternative in some use cases and at some scales to transformers. Basically, it would require less compute time and less storage for the same input and similar outputs. I am looking forward to seeing someone bring this to a workable demo—the paper presented lots of graphs that left me wondering how this would be any different or better from the perspective of a user.
A few final thoughts
- The presenters were very careful about their claims, and made several caveats about what the findings indicate. Insofar as the paper was hard to understand, I did not know the caveats existed until others asked questions to clarify diagrams and claims. All this is to say, the implications of this type of highly technical research requires a great deal of knowledge and translation.
- Though I am not a builder, I knew a little about RNNs from just knowing the history of AI developments. Plenty of timelines exist that place RNNs to the left before the transformer era. I had assumed RNNs were dead. Yet this paper made me realized those making these technologies are distinct from those narrativizing them as products and opportunities. Claiming transformers are the future is an opportunity narrative (”bigger, better, faster…now in titanium!”) as much as a claim about comparative performance. In addition, the paper made it clear that builders are cross-pollenating ideas in ways that are not obvious to non-builders in this space, and especially consumers of these services. There is a lot of room to make these ideas accessible and valuable beyond their technical accomplishment.
-
I am not sure what the right term is here. I’ll use the term builders to refer to engineers, developers, data scientists, and the like who are deeply immersed in the mechanics of AI. These roles are radically different and barely hang together. Likewise, I use the term non-builders to refer to everyone else. In discussions with peers, I have heard the technical and non-technical or expert and non-expert. I don’t like these terms because what is deemed technical and expert is highly debatable, and entrenched in the history and market of valuing certain types of knowledge, production, and work. Admittedly, so does builder/non-builder, but these terms feel more fitting to describe what different people are expected to do relative to AI. If someone has a concise and easy to use distinction, please send it my way. ↩︎